Unicode Support
Unicode is a map of characters in the world's languages to a fixed number or code-point. This document covers Cobalt Strike's support for Unicode text.
Encodings
Unicode is a map of characters to numbers (code-points), but it is not an encoding. An encoding is a consistent way to assign meaning to individual or byte sequences by mapping them to code-points within this map.
Internally, Java applications, store and manipulate characters with the UTF-16 encoding. UTF-16 is an encoding that uses two bytes to represent common characters. Rarer characters are represented with four bytes. Cobalt Strike is a Java application and internally, Cobalt Strike is capable of storage, manipulation, and display of text in the world's various writing systems. There's no real technical barrier to this in the core Java platform.
In the Windows world, things are a little different. The options in Windows to represent characters date all the way back to the DOS days. DOS programs work with ASCII text and those beautiful box drawing characters. A common encoding to map numbers 0-127 to US ASCII and 128-255 to those beautiful box drawing characters has a name. It's codepage 437. There are several variations of codepage 437 that mix the beautiful box drawing characters with characters from specific languages. This collection of encodings is known as an OEM encoding. Today, each Windows instance has a global OEM encoding setting. This setting dictates how to interpret the output of bytes written to a console by a program. To interpret the output of cmd.exe properly, it's important to know the target's OEM encoding.
The fun continues though. The box drawing characters are needed by DOS programs, but not necessarily Windows programs. So, with that, Windows has the concept of an ANSI encoding. It's a global setting, like the OEM encoding. The ANSI encoding dictates how ANSI Win32 APIs will map a sequence of bytes to code-points. The ANSI encoding for a language forgoes the beautiful box drawing characters for characters useful in the language that encoding is designed for. An encoding is not necessarily confined to mapping one byte to one character. A variable-length encoding may represent the most common characters as a single byte and then represent others as some multi-byte sequence.
ANSI encodings are not the full story though. The Windows APIs often have both ANSI and Unicode variants. An ANSI variant of an API accepts and interprets a text argument as described above. A Unicode Win32 API expects text arguments that are encoded with UTF-16.
In Windows, there are multiple encoding situations possible. There's OEM encoding which can represent some text in the target's configured language. There's ANSI encoding which can represent more text, primarily in the target's configured language. And, there's UTF-16 which can contain any code-point. There's also UTF-8 which is a variable-length encoding that's space efficient for ASCII text, but can contain any code-point too.
Beacon
Cobalt Strike's Beacon reports the target's ANSI and OEM encodings as part of its session metadata. Cobalt Strike uses these values to encode text input, as needed, to the target's encoding. Cobalt Strike also uses these values to decode text output, as needed, with the target's encoding.
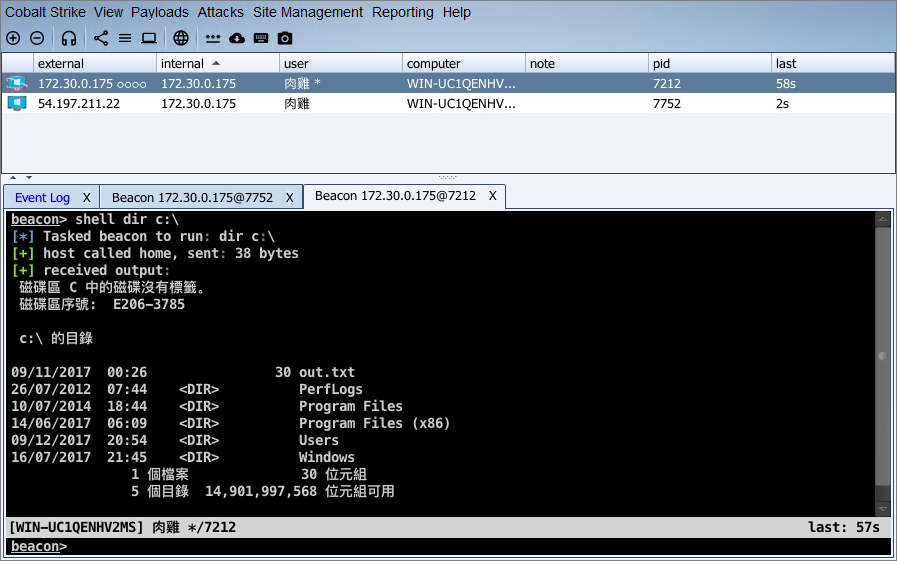
In general, the translation of text to and from the target's encoding is transparent to you. If you work on a target, configured to one language, things will work as you expect.
Different behaviors, between commands, will show up when you work with mixed language environments. For example, if output contains characters from Cyrillic, Chinese, and Latin alphabets, some commands will get it right. Others won't.
Most commands in Beacon use the target's ANSI encoding to encode input and decode output. The target's configured ANSI encoding may only map characters to code-points for a handful of writing systems. If the ANSI encoding of the current target does not map Cyrillic characters, make_token will not do the right thing with a username or password that uses Cyrillic characters.
Some command, in Beacon, use UTF-8 for input and output. These commands will, generally, do what you expect with mixed language content. This is because UTF-8 text can map characters to any Unicode codepoint.
The following table documents which Beacon commands use something other than the ANSI encoding to decode input and output:
| Command | Input Encoding | Output Encoding |
|---|---|---|
| hashdump | UTF-8 | |
| mimikatz | UTF-8 | UTF-8 |
| powerpick | UTF-8 | UTF-8 |
| powershell | UTF-16 | OEM |
| psinject | UTF-8 | UTF-8 |
| shell | ANSI | OEM |
For those that know mimikatz well, you'll note that mimikatz uses Unicode Win32 APIs internally and UTF-16 characters. Where does UTF-8 come from? Cobalt Strike's interface to mimikatz sends input as UTF-8 and converts output to UTF-8.
SSH Sessions
Cobalt Strike's SSH sessions use UTF-8 encoding for input and output.
Logging
Cobalt Strike's logs are UTF-8 encoded text.
Fonts
Your font may have limitations displaying characters from some writing systems. To change the Cobalt Strike fonts:
Go to Cobalt Strike -> Preferences -> Cobalt Strike to change the GUI Font value. This will change the font Cobalt Strike uses in its dialogs, tables, and the rest of the interface.
Go to Cobalt Strike -> Preferences -> Console to change the Font used by Cobalt Strike's consoles.
Cobalt Strike -> Preferences -> Graph has a Font option to change the font used by Cobalt Strike's pivot graph.