HA FAQ
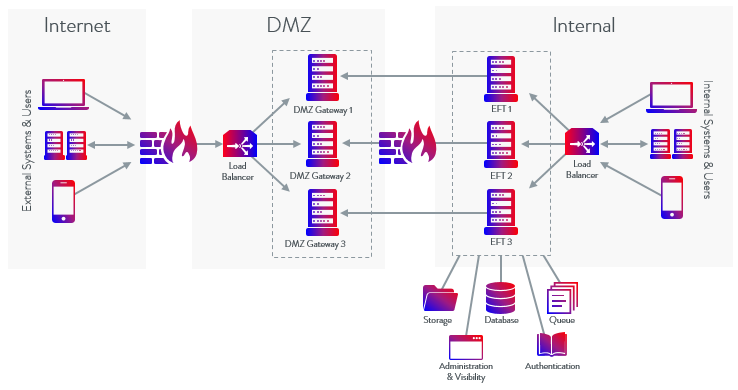
EFT Enterprise can be configured in an active-active cluster configuration, known as EFT High Availability (HA). In an HA deployment, two or more EFT installations can be configured in an active-active cluster with a shared configuration. EFT acts as its own cluster manager and requires a network load balancer (NLB) to distribute incoming protocol traffic. EFT HA nodes process file transfers at the network level as the NLB directs traffic to it, and can process Folder Monitor and Timer Event Rules in a round-robin fashion (i.e., executing the event actions on the first node, then the second, and so on until it comes back to the first node in the list). An example 3-node deployment is shown below. Having at least 3 nodes allows you to take down one node for maintenance and still have 2 active nodes for HA.
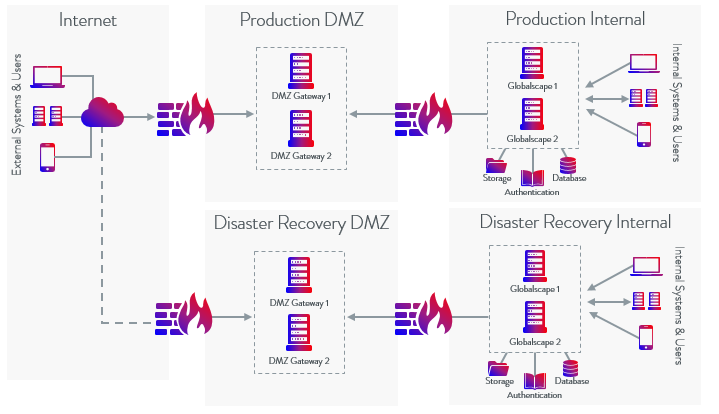
You can also install EFT HA in a DR environment:
For best results, before beginning an HA installation, please review all of the information below and refer to the references linked.
Consider the facts below before creating an HA cluster
Installation:
-
To install EFT as part of a high availability (HA) cluster, refer to Active-Active HA Cluster--Installing or Upgrading the Server.
-
For true business continuity, you should have a minimum of three nodes, so that when one server goes down, nodes on other servers continue to process transactions in high availability, meeting those stringent uptime requirements.
-
When EFT is running in HA mode and sharing a network resource, you must run the EFT server service with a Log On account that can access that shared network resource.
-
Nodes should be brought online one at a time to avoid getting the nodes out of sync. A node can get out of sync if 1) on administrator login, if the configuration in memory does not match the configuration file on the shared drive; or 2) when the node fails to receive a configuration change message. In either case, the EFT server service will restart and load the latest configuration.
-
You can configure additional Sites on non-HA nodes with other authentication to cooperate with the HA-clustered Sites. For example, you could use an AD-authenticated Site on a non-HA node for domain user uploads and downloads, but use the Globalscape, AD, or LDAP-authenticated Sites in the HA cluster for load balancing Event Rules that take place on the files transferred. The non-clustered AD Site would transfer files using the HA shared configuration path as the Site root folder or using virtual folders, while the Event Rule Actions take place on the files on the HA Site.
-
If you are using DMZ Gateway®, each EFT must have its own DMZ Gateway; the DMZ Gateway cannot be shared among nodes.
-
HA nodes must listen on all IP addresses, rather than each listening on a specific IP address. Do not change the Listening IP address for an HA node. A registry value can be configured to have a different IP address for each node. Refer to Knowledgebase article #11225 for details.
-
The default EFT options for DoS/Flood Protection and Login Security settings are designed for each IP to have a single user’s activity. These settings can cause EFT to ban the load balancer’s IP or intermittently block its activity when all user connections are using the load balancer’s IP. These settings should be disabled when using a load balancer. It’s also a good idea to set an IP access rule to allow the load balancer IP on EFT just in case the settings are accidentally enabled later.
-
To make an HA node a stand-alone server, you must uninstall EFT and then reinstall as a stand-alone server. Please contact Sales, Support, or Professional Services for assistance in migrating any existing non-HA deployments to a corresponding HA configuration.
-
HA can only be installed as a new installation; upgrades from 6.4.x and 6.5.x to an HA installation are not allowed. A stand-alone server cannot be converted to an HA node.
-
On HA installations, the EFT server service is configured to restart upon failure on the Recovery tab of the service's properties. (Non-HA installations are configured to "take no action" upon failure.)
-
You cannot backup in standby and restore in HA or vice versa. You can run restore on any node in the HA cluster. You can restore shared data, node-specific data (listening IP address, DMZ Gateway settings, registration) or both. When the restore process begins, other nodes stop with -1 error. This triggers them to be restarted by Windows Service Manager, at which point those other nodes will wait for restore operation to complete. Once the restore has completed on one of the nodes, the other nodes that had been waiting will proceed with loading configuration. After the restore completes, the node that did restore also restarts in the same way. Thus, all nodes in the cluster have restarted with restored configuration up and running.
-
HA Shares should NOT reside on a Unix Samba share. EFT HA environments have a difficult time recovering from network failures that occur on the master node's system.
Configuration:
-
If using SAML (Web SSO) in an HA environment, SAML needs to have the IDP's public key saved in the HA shared drive.
-
The FTP.cfg file for the clustered EFT nodes and users' files must be stored on a network share (e.g., CIFS or SMB).
-
After installation, the shared path (e.g., \\myserver\HA_config) is shown on the Server's High Availability tab > Config Path. The shared configuration file PATH cannot be changed in the administration interface. KB #11260 describes how to change the path in the registry.
-
On an HA-clustered Site, the Usr folder (e.g., \inetpub\EFTRoot\mySite\Usr\), which contains the users' folders, is stored in the shared configuration path.
(e.g., \\x.x.x.x\inetpub\EFTRoot\mySite\Usr\username) -
When using Encrypted folders, you can only encrypt files in the directory hierarchy of the Site's root folder. Make sure that the Site root folder on the Site > General tab is pointing to the correct path. That is, if your HA config drive is on D:\HAConfig\, you should edit the site root folder to point to D:\HAConfig\InetPub\EFTRoot\MySite.
-
When creating an LDAP Site on an HA node, the User list refresh interval setting is disabled. The user list must be synchronized on all nodes at the same time.
-
A local configuration path for each node must also be specified for each node for local caching. When configuration changes are made to SSH, trusted SSL certificates, OpenPGP key materials, and AML files (Advanced Workflow Engine workflows), those files are cached locally, and uploads are safely synchronized to the shared config path. The other nodes then update their local cache from the central location. Thus, the central share always contains the current version of those files. When, for example, a new SSL Cert or AML file is created, the creator directly adds/modifies the files on the network share then tells the other nodes that the file was modified/created and they need to update their local cache (i.e., copy the file to their local ProgramData directory).
-
When using HA, you need to specify a unique location (local) for the log files. This is for troubleshooting purposes (to know on which node the issue occurred). Also, having two nodes write to the same file causes issues with file locking, which will cause data in the logs to be lost. For visibility into node status, enable cluster logging. Logging.cfg has new logging options specifically for HA. When configuring RSA in an HA environment be sure to have the sdconf.rec file stored locally for each node. Each node MUST have its own copy of sdconf.rec.
-
When configuring an HA environment, the user home folder paths (by default, C:\Inetpub\) must not reside under the shared configuration, otherwise the encryption will fail because it will consider Inetpub a reserved path. A workaround is to create a separate share for \Inetpub\ (user home folders) so that it doesn't trigger the reserved path error.
-
Proper communication among nodes requires:
-
Network adapters on all HA nodes that enable Reliable Multicast Protocol (for the adapters that provide the route between EFT HA nodes)
-
All nodes must be able to send and receive multicast messages, which requires they been on the same LAN subnet
-
L2 Switch between physical computers that host an EFT HA node (physically or virtually) must enable traffic on the LAN segment between HA nodes. Typically, this means enabling IGMP Snoop and IGMP Querier; however, complex deployments (including VPN or MPLS networks between nodes) might require packet encapsulation, such as GRE, to allow packets to operate properly between nodes.
-
Firewalls between HA nodes, and on the computers hosting EFT, must allow the traffic (both multicast and unicast) to pass in and out of the computers. (Windows Firewall will automatically enable the proper ports when enabling MSMQ.). For physical switches, be sure there are no packet filtering rules that prevent packets of type 113 to flow between nodes.
-
If you do not want to use unicast or multicast on your network, you should create a new VLAN for EFT communications. Refer to Knowledgebase articles #11221 and #11276 for more information about MSMQ, VLAN, and EFT.
-
HA mode of operation for supports IPv6 addressing for inbound and outbound connections. The message queue addressing of nodes within the cluster is not supported on IPv6 addresses. Message queue addressing uses NetBIOS names, not IP addresses, and could be tied to IPv4 on the local LAN subnet that all nodes share.
-
When configuration changes are made to SSH, trusted SSL certificates, OpenPGP key materials, and AML files (Advanced Workflow Engine workflows), those files are cached locally, then safely synchronized to the network share. The other nodes then update their local cache from the central location. Thus, the central share always contains the current version of those files.
-
Folder Sweep and archive should be enabled on load balanced Folder Monitor rules to clean up and notify on any events that occur when the primary Event Rule monitor goes down. It is possible to lose some events between when the primary goes down and the next node takes over.
-
The "Run On One of" feature in Event Rules currently only supports computer (NetBIOS) names. Refer to Event Rule Load Balancing for more information about the "Run On One of" feature.
-
Do not start or provision a new node immediately after making changes to the Event Rule configuration. Give the system at least 30 seconds to process and synchronize the configuration changes.
-
Because all of the nodes fire User Account Created events, each node also runs all User Account Created event rules. Therefore, to avoid sending multiple email notifications (for example), you should add an "If node name" Condition to the rule so that only one node sends the notification (or performs other Actions).
-
When operating in HA mode, the Timer and Folder Monitor Event Rules will execute on ALL of the nodes of the cluster unless you specify at least one High Availability node on which to operate. Define a default node for load balancing, as described in High Availability Tab of a Server.
-
In every HA cluster, there will be a "Master" node that performs the Event Rule load balancing assignments.
-
Any node may be master; if a master node goes offline, another node will take over as master. Whichever node declares master first becomes master. A node doesn’t take over as master until at least one load-balanced Event Rule exists on the system. Prior to a load-balanced Event Rule’s existence, all nodes will claim to be master. A master can go down if, for example, MSMQ is stopped, or the network can no longer communicate with the master or the EFT server service for some reason goes down.
-
Every 10 seconds each node broadcasts a heartbeat to communicate that they are alive and online. This serves two purposes: 1) Notifies that the master node is up, if the master goes down, then a new node will resume master responsibilities and broadcast that they are now master; 2) Notifies the cluster that the node is online and should be included to handle load-balanced Event Rules.
-
The ARM reports identify nodes based on computer name. If the node's computer name changes, ARM will see it as a new node and not associate it with the old computer name. (ARM installs an additional set of reports in a "High Availability" folder. These reports are a duplicate of the existing reports, except they report based on Node name.)
-
The API was updated to include HA-specific calls.
-
Only one node at a time is allowed to use the administration interface or COM connection. That is, you cannot administer more than one node at a time. (However, more than one administrator can administer the SAME node at the same time, just as in non-HA configurations.) Attempts to administer more than one HA node at a time will prompt an error on nodes other than the first.
MSMQ or Unicast:
Microsoft Message Queueing (MSMQ) to distribute messages among nodes in the cluster is used by default. Unicast can be used instead of MSMQ. Refer to Unicast for details.
Event Rules:
Auditing and Reporting:
COM API:
Non-High Availability mode vs. High Availability mode EFT
|
Function |
Non-High Availability mode |
High Availability mode |
|---|---|---|
|
Startup |
Searches for FTP.CFG’s in different folders, tries FTP.BAK’s to handle broken configuration, etc. Always creates "clean" configuration if no FTP.CFG/FTP.BAK is loaded. |
Loads only <PATH>\FTP.CFG. Creates "clean" configuration only if no FTP.CFG present in the <PATH> folder. Fails to start if cannot load existing <PATH>\FTP.CFG. |
|
Shutdown |
Updated FTP.CFG with latest settings |
Does not update FTP.CFG |
|
Authentication managers |
GS, NTAD, ODBC, LDAP |
Globalscape, NTAD, and LDAP |
|
User database refresh |
Allowed |
Not allowed |
|
PCI cleanup (administrator/user remove/disable for inactivity and send Password Expiration Notifications) |
Nightly timer + Every time server deals with user/administrator (user/administrator connection, exposing user/administrator to GUI/COM etc.) |
Nightly timer |
|
Client Expiration |
Every time when server deals with user (user connection, exposing user to GUI/COM etc.) |
Nightly timer |
|
Turning off Autosave and using "ApplyChanges" via COM |
Allowed |
Not allowed |
|
GUI/COM connection |
Always allowed |
Only one node at a time is allowed to serve GUI/COM connection |
|
Saving changes made by administrator to FTP.CFG |
Background task accumulating changes and saving settings |
Only one node can be administered at a time. As soon as you log off of the node on which you've made changes and then log on to second node, those changes would be updated on the second node. |
|
Server restore from backup |
Allowed |
Allowed |
|
Trial state |
FTP.CFG + registry (duplicated) |
Registry |
|
OTP passwords for clients |
Allowed |
Not allowed |
|
Legacy password hashes |
Allowed |
Not allowed |
|
User lock state |
Continues after service restart |
Breaks after service restart |
|
Invalid login history |
Continues after service restart |
Resets on service restart |
Related topics